What is Fuzzing?
Fuzzing 정의
Fuzzing ?

Fuzzing은 불리는 자동화된 소프트웨어 테스트의 기술에 일종으로, 퍼징 대상의 프로그램에 Untrust Input에 무작위 데이터를 대입하여 예기치 못한 반응, 즉 Crash, 메모리 누수등 취약점을 발생시키는 테스트 기법입니다.
Untrusted Input에 모든 테스트 내용을 사람이 직접 입력하기에는 너무나도 많은 시간이 낭비되므로 자동화시켜서 테스트할 수 있는 AFL과 libFuzzer와 같이 쉬운 퍼징 프레임워크을 이용하여 Fuzzing을 진행해 효율적이며 빠르게 취약점을 찾을 수 있습니다.
Fuzzing 테스트 이후 검출된 Crash, 메모리 누수등에 대한 결과 값, 파일을 가지고 어떠한 함수, 메모리에서 어떤 취약점이 발생되었는지를 확인할 수 있다.
그러면 왜 할까?
Fuzzing의 목적은 모든 프로그램 내에 항상 존재하는 버그가 있다는 가정을 전제합니다. 따라서 체계적인 접근 방식을 통해 이러한 버그를 찾아야합니다.
Fuzzing은 기계적인 접근방식으로 기존 소프트웨어 테스트 기술(코드 리뷰, 디버깅)에 또 다른 관점을 추가 할 수 있습니다. 이를 완전히 대체하지는 못하지만 다른 단점을 보완해줄 수 있는 합리적인 보완책입니다.
Fuzzing 종류
Black-box fuzzing
테스트 대상에 대한 내부 구조나 동작 방식을 모르는 상태에서 무작위 데이터나 테스트 케이스를 입력으로 사용하여 취약점을 찾는 기법입니다.
일반적으로는 입력 데이터의 크기, 형식, 구조 등을 무작위로 변형하여 퍼징을 수행합니다.
White-box fuzzing
테스트 대상의 내부 구조나 동작 방식을 분석하여, 가능한 모든 경로에 대해 테스트 케이스를 생성하여 취약점을 찾는 기법입니다.
화이트박스 퍼징은 블랙박스 퍼징보다 효율적인 결과를 보여줄 수 있습니다.
Grey-box fuzzing
테스트 대상의 일부 내부 정보를 알고 있는 상태에서 퍼징을 수행하는 기법입니다. 일반적으로는 블랙박스 퍼징과 화이트박스 퍼징을 혼합하여 사용합니다.
Dumb Fuzzing
덤 퍼징은 테스트 케이스를 생성하기 위해서 진단하고자 하는 프로그램에 대한 이해가도 없어도 된다.
기존 데이터 구조에 대한 지식이 전혀 없는 상태에서 아무런 값을의 데이터를 입력하는 퍼징기술이다.
추가적인 로직이나 분석을 수행하지 않아 여러 Fuzzing 기술중에서 가장 긴 Runtime을 가질 것이다.
Smart Fuzzing
Dumb Fuzzing보다 더욱 효율적으로 수행하는 Fuzzing 기술로 어플레킹션의 입력 값을 분석하여 해당 입력 값에 대한 유효성 검사나 제약조건을 파악한 뒤 수행합니다.
만약 알집을 퍼징한다하면 알집에서 구현되어있는 format 정보를 파악하고 해당 file format에 맞게 testcase를 생성해야한다는 소리이다.
Coverage guided Fuzzing
해당 기법은 일반적이며 가장 효과적으로 권장하는 기법이기도 합니다. 테스트 케이스가 어플리케이션의 코드에서 얼마나 많은 블록(브랜치)을 실행하는지에 따라 새로운 입력을 생성하고 선택하는 방식으로 동작하는 퍼징 방법입니다.
즉, 이전 퍼징에서 실행되지 않았던 코드 블록을 우선적으로 실행시키는 새로운 테스트 케이스를 생성하도록 설계되어 있습니다.
그렇다면 코드 커버리지가 높으면 그만큼 프로그램에 대한 많은 분기를 돌게 되고, 이를 통해 더 많은 버그를 찾아낼 수 있는 이점이 있습니다.
Stream Fuzzing
TCP, UDP 등의 네트워크 프로토콜을 이용하여 입력값을 전송하는 방식으로, 네트워크 서비스의 취약점을 찾는 데에 사용됩니다.
(제가 작성한 것을 제외하고도 수많은 기법들이 존재합니다!)
과정

프로그램을 퍼징하기전에 앞서 설명드린 내용을 잘 이해하셔야 합니다. 크게 4개 과정으로 볼 수 있습니다. Untrust Input 삽입하여 프로그램 실행을 하고 이에 대한 결과를 확인하여 취약점 및 버그를 확인하는 과정입니다.
아래의 과정은 Window 환경에서 Fuzzing을 하는 WinAFL를 예시로 설명드리겠습니다.
프로그램 선택
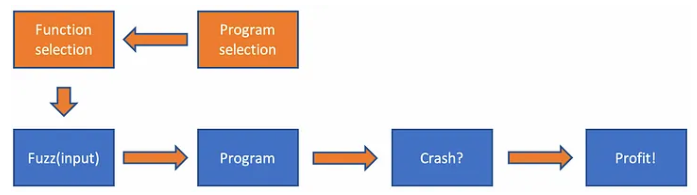
퍼징을 하기 위해서는 당연히 어떤 프로그램을 퍼징할 지를 선택해야합니다. 하지만 프로그램 하나를 가지고 전체를 돌리기에는 엄청난 소요시간이 필요하겠죠?
그렇기에 수많은 내부 함수 중에서 입력 값 혹은 파일을 받는 함수를 이용합니다. 이를 이용한다는 것은 입력 값을 persistent하게 주입이 가능하며 불필요한 함수 로딩을 줄일 수 있습니다.
타겟 함수 선정
프로그램 전체를 대상으로 퍼징을 돌릴 시 무수히 많은 시간이 걸리므로 Untrust Input를 받는 함수만을 퍼징하는 것이 제일 좋습니다.
이에 우리의 입력 값을 어느 함수에서 받고 어떻게 처리하는지 알아야 하고, 그것이 타겟 함수가 됩니다.
이 타겟 함수를 선정하는 조건으로는 아래와 같습니다.
-
타겟하고자 하는 함수 내에서
Input파일을Open -
해당 파일을
파싱 -
타겟하고자 하는 함수 내에서
Input파일을Close -
이후
return까지 정상적으로 실행
이 네 조건을 만족하는 함수가 바로 fuzzing target function이 됩니다.
Harness
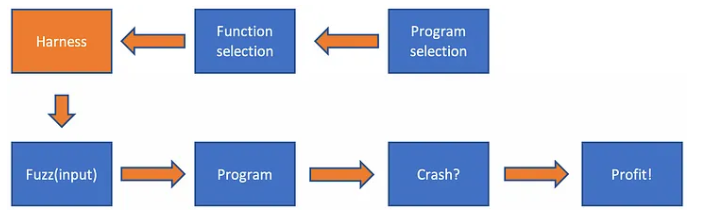
WinAFL 사용하기 위해서는 Harness 라는 작업이 필수적으로 필요합니다. 이게 무엇이냐?
Fuzzing이 정상 작동하는지 target function에 입력값이 제대로 들어가는지 미리 확인하기 위해 필요한 구조를 설정하고 대상 함수에 필요한 초기화를 완료하려면 가벼운 프로그램이 필요합니다. 쉽게 말해서
프로그램의 실행 및 입력값을 전달하기 위한 코드로 target function을 실행하고 입력 값을 전달하는 코드로 주로 유닛 테스트를 수행할 떄 사용하는 것과 유사한 방식으로 작성합니다.
또한 Windows는 GUI를 사용하기에 이에 대한 resource를 많이 사용하여 fuzzing에 대한 어려움이 있기에 이를 해결하기 위해서 Harness를 작성한다.
Corpus
WinAFL 사용하기 위해서는 Harness 라는 작업이 필수적으로 필요합니다. 이게 무엇이냐?
Fuzzing이 정상 작동하는지 target function에 입력값이 제대로 들어가는지 미리 확인하기 위해 필요한 구조를 설정하고 대상 함수에 필요한 초기화를 완료하려면 가벼운 프로그램이 필요합니다. 쉽게 말해서
프로그램의 실행 및 입력값을 전달하기 위한 코드로 target function을 실행하고 입력 값을 전달하는 코드로 주로 유닛 테스트를 수행할 떄 사용하는 것과 유사한 방식으로 작성합니다.
해당 테스트가 정상 작동하는지 계측하는 서브 프로세스를 이용하게 되는데 DynamoRIO라는 것을 이용합니다.
Fuzzing !
이후 Fuzzer를 작동시키는게 Fuzzing은 길고 복잡한 프로세스이므로 RAM이 많은 기기가 유용합니다. 또한 수많은 임시 파일을 디스크에 쓰기 때문에 스토리지 용량도 중요합니다.

이후에는 여러 커뮤니티로 확인해본 WinAFL 사용법 및 퍼징 테스트하는 것을 포스팅해보도록 하겠습니다!
참고
https://medium.com/csg-govtech/starting-to-fuzz-with-winafl-ecc41661220c
https://www.coalfire.com/the-coalfire-blog/fuzzing-common-tools-and-techniques?feed=blogs